1. 크롤링이란?
크롤링(crawling) 혹은 스크레이핑(scraping)은 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위다.
크롤링하는 소프트웨어는 크롤러(crawler)라고 부른다.
출처: 나무위키
예를 들어
우리가 음원 사이트의 음원 정보를 엑셀에 출력해야 한다면 일일이 수작업으로 작성할 수 있지만 굉장히 비효율 적이다. 그래서 크롤링을 사용하면 음원 사이트 HTML에서 내가 필요한 정보만 뽑아 추출할 수 있다.
2. 코드 구현
1. 라이브러리
- Axios는 node.js와 브라우저를 위한 Promise 기반 HTTP 통신 라이브러리이다.
- cheerio는 문자열로 구성된 html 코드를 분석하여 서버에서도 원하는 document 속성이나 text를 탐색 및 수집할 수 있도록 하는 라이브러리이다.
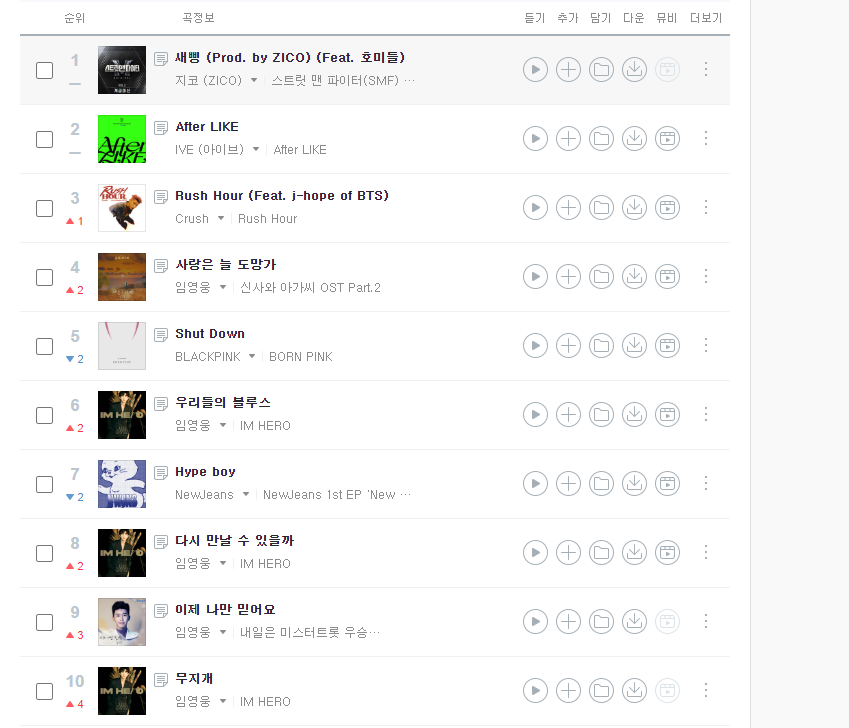
2. 크롤링할 페이지
크롤링 홈페이지는 지니 뮤직 top 200을 참고했다.
2. Examples
const axios = require("axios");
const cheerio = require("cheerio");
const getHtml = async () => {
try {
// 1
const html = await axios.get("https://www.genie.co.kr/chart/top200");
let ulList = [];
// 2
const $ = cheerio.load(html.data);
// 3
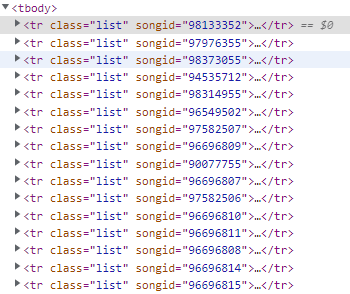
const bodyList = $("tr.list");
bodyList.map((i, element) => {
ulList[i] = {
rank: i + 1,
// 4
title: $(element).find("td.info a.title").text().replace(/\s/g, ""),
artist: $(element).find("td.info a.artist").text().replace(/\s/g, ""),
};
});
console.log("bodyList : ", ulList);
} catch (error) {
console.error(error);
}
};
getHtml();1. axios로 지니뮤직 top 200 페이지의 html 데이터를 받아온다.
2. load: html을 인자로 받아 cheerio 객체를 반환한다.
3. body 내에 크롤링할 정보가 있는 태그를 인자로 받아 해당되는 모든 태그를 배열로 반환한다.
4. title, artist 등의 문자열을 추출하기 위해서 list 클래스 태그 배열(bodyList)을 순회한다. 그리고 find 메서드에서 각각 필요한 문자열을 가지고 있는 태그를 인자로 받아 title, artist 등의 문자열을 추출할 수 있었다.

뒤에 정규표현식을 사용한 이유 : 정규표현식을 사용하지 않았을 때 아래와 같이 공백이 출력되었다. (페이지마다 다름)

text 메서드 뒤에 정규표현식을 사용함으로 앞 뒤 공백만 제거할 수 있다.
replace(/^\s+|\s+$/gm, "")3. 결과

임영웅님 대단합니다...
추가로 찾아봐야 할 부분

위와 같은 형태로 있을 때 nth-child를 사용해도 1과 span 아래에 있는 text가 합쳐져서 출력하게 된다.
rank: $(element).find("td.number:nth-child(2)").text().replace(/\s/g, "")
// 1로 넣었을 때는 빈 값 출력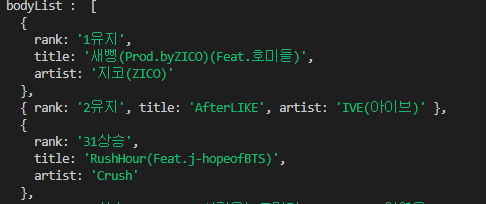
처리할 수 있는 함수가 있는지 문서를 한 번 더 봐야겠다.
'node.js' 카테고리의 다른 글
| [Node] package.json.lock 파일의 역할 (0) | 2023.02.05 |
|---|---|
| [Node] Mac OS에서 NVM 설치하기 (0) | 2023.01.28 |
| [node.js] 객체지향 프로그래밍이란? (Typescript) (0) | 2022.08.09 |
| [node.js] nvm으로 프로젝트별 node version 관리하기 (0) | 2022.07.07 |
| [node.js] package.json script 실행 파일 명령어 설정 ( --global ) (0) | 2022.06.24 |